Select a dataset
Every query in Explore starts with a dataset selection. Selecting the right dataset before running a query improves both the speed and relevance of your results.
Why your dataset selection matters
Use dataset selection for:
- Faster queries: Explore searches only within the selected dataset rather than across all your data, reducing query time and resource usage.
- Focused results: Results are scoped to the data type you are investigating, so logs queries return log events and spans queries return trace data — no noise from unrelated signal types.
- Access to internal data: System datasets expose Coralogix-managed metadata that is not part of your ingested data, such as alert history and audit events, without interfering with your application data.
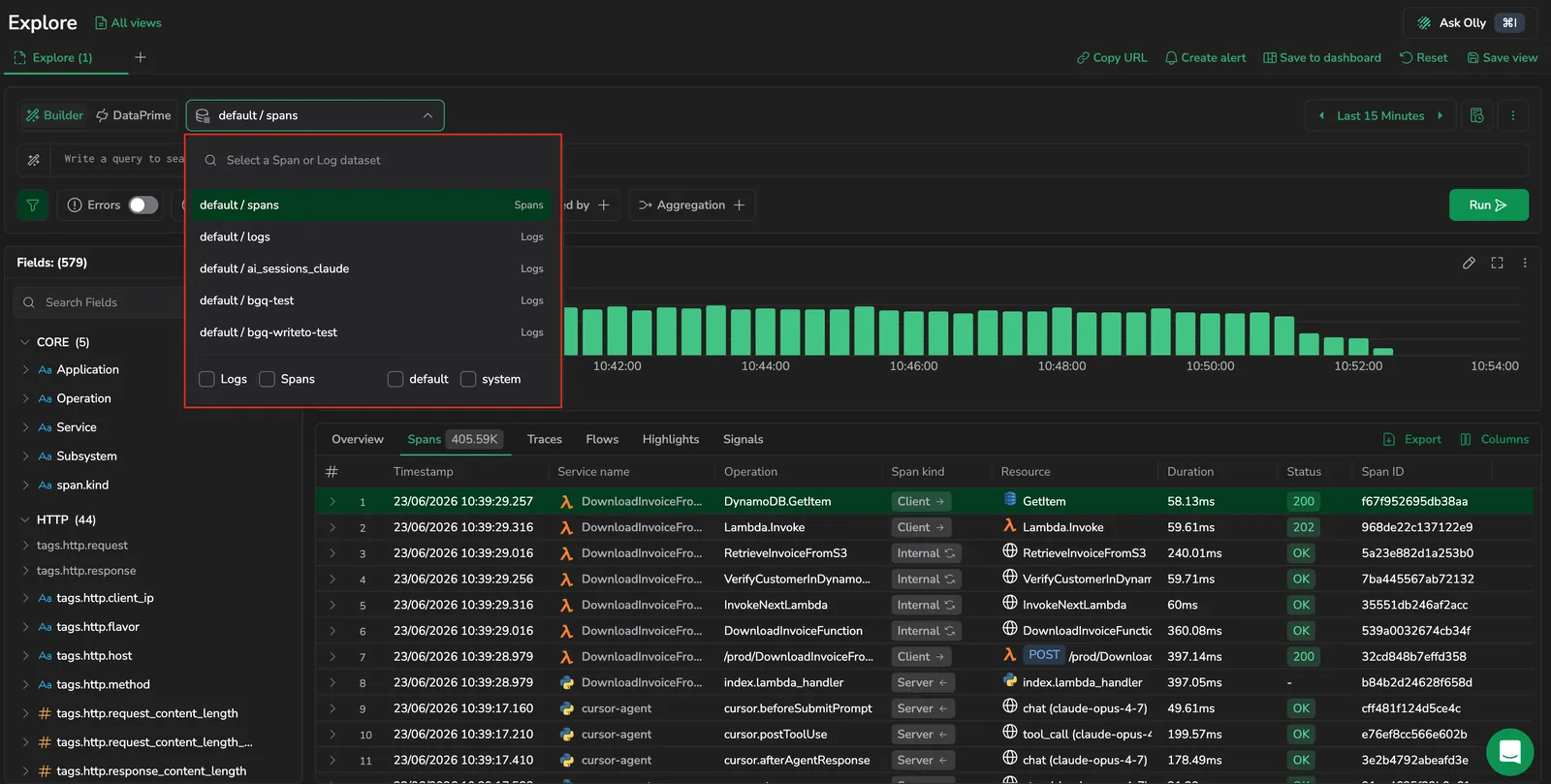
How the selector works
The dataset selector sits inside the query builder and shows every dataset available to your team in a searchable dropdown. Each row is rendered as <dataspace> / <dataset> (for example, Default / logs) with an entity-type pill on the right.
At the bottom of the dropdown, three checkboxes — Logs, Spans, and Other — narrow the list to the entity types you care about.
When you switch to a different dataset, Explore:
- Resets the query to the empty state for the new dataset.
- Resets the column layout to the new entity type's defaults.
- Preserves the current time range.
Dataspaces and datasets
Data in Coralogix is organized into dataspaces and datasets.
- A dataspace is a logical container that groups related datasets and applies shared configuration.
- A dataset is the actual data store within a dataspace — the records you query.
For example, logs is a dataset inside the default dataspace. In DataPrime you reference it as source default/logs (or simply source logs). In Builder mode, you just pick it from the dataset selector — no source clause appears in the Lucene query you type.
| Dataset | Dataspace | Entity type |
|---|---|---|
logs | default | Logs |
spans | default | Spans |
| User-defined datasets | default | Any dataset you create under default/ |
| System datasets | system | alerts.history, aaa.audit_events, and others |
rum.events | RUM | RUM events ingested from the browser SDK |
/logs
The logs dataset is the default selection in the default dataspace. It contains your ingested log data and is the starting point for most log investigations.
When you select logs, you can query with Lucene or DataPrime, apply filters, group results, and visualize log distributions.
/spans
The spans dataset contains your distributed tracing data. Selecting spans lets you search traces, inspect spans, and drill into service dependencies.
Frequent Search datasets
The frequentsearch/logs and frequentsearch/spans datasets query Coralogix's Frequent Search index — a faster path for high-velocity, recent data. Select these from the dataset selector when you want quicker iteration over the most recent slice of your logs or spans. Query syntax, fields, and visualizations behave the same as logs and spans, with two differences:
- Span Relation filters are not supported on Frequent Search datasets. Explore clears them when you switch to or restore a Frequent Search dataset.
- 10-second auto-refresh is exclusive to Frequent Search. The auto-refresh control in the time-range picker unlocks a 10-second interval only when a Frequent Search dataset is active.
User-defined datasets
User-defined datasets are custom datasets you create under the default/ dataspace to isolate specific log streams. After creating a dataset in Dataset Management and routing logs to it via a TCO policy, the dataset is available in the Explore dataset selector.
Select a user-defined dataset from the dataset selector. In DataPrime, Explore references it as source default/<dataset-name>. You can then search, filter, and visualize the data as you would with logs or spans.
See User-defined datasets for setup instructions.
System datasets
System datasets are read-only datasets maintained by Coralogix. They contain internal observability data such as alert history, audit events, and limit violations.
| Dataset | Description |
|---|---|
system/aaa.audit_events | Audit trail of system activity for compliance and access monitoring. |
system/alerts.history | History of alert evaluations and trigger events. |
system/engine.queries | Record of user queries for introspection and optimization. |
system/engine.schema_fields | Field-level schema snapshots over time. |
system/labs.limit_violations | Records of configured limit violations. |
system/notification.deliveries | Lifecycle of outbound alert notifications. |
system/dataplan.quota_events | Quota-related events: allocations, consumption, and threshold breaches. |
system/dataplan.usage_events | Aggregated team data usage events. |
System datasets must be enabled before they can be queried. Navigate to Data Flow, then Dataset Management to enable or disable them.
Non-timestamped datasets
Some datasets do not include a timestamp field. Explore supports querying these datasets with pre-built queries and pre-configured graphs, so analysis is accessible without building queries from scratch.
When you select a non-timestamped dataset:
- The time range picker is disabled and shows the tooltip The selected dataset is not partitioned by time.
- Auto-refresh is force-cleared.
- The Visualize as selector is locked to Table until you add a Grouped by clause.
Use the pre-built queries and graphs as a starting point.
Spans sub-view
When the selected dataset has the Spans entity type, the result panel exposes additional view modes — Spans, Traces, Flows, Analyze, RED metrics — alongside the standard tabs. The current sub-view is captured in the URL so saved views and shared links restore the same sub-view.
Next steps
Review the role-based and policy-based permissions required to use Explore in Explore permissions.